Last updated Sat 4 May 2024 11:23:22 EST
In this article we're going to explore a simple yet powerful way to build and train a dataset for hand gesture recognition, specifically still hands. We are also going to explore applications of this approach on moving hands, and possible future developements to make this a complete real-time ASL interpreter.
It is pertinent to address a specific limitation of this CNN model in recognizing the letters ’J’ and ’Z’ within American Sign Language (ASL) spelling. This constraint stems from the model’s reliance on still images to identify letters. In ASL, both ’J’ and ’Z’ are represented not only through specific hand shapes but also through distinctive movements—’J’ is conveyed by drawing a ’J’ shape in the air, and ’Z’ involves tracing a ’Z’ pattern.
The main idea for capturing and identifying movement saving a 3-frame rolling picture, and using that to recognise the letters.

The original dataset found on Keggle contained 27,455 training images, 7,172 testing images. All the images are 28x28 in resolution and 8-bit RGB.

In the development of our convolutional neural network (CNN) for real-world American Sign Language (ASL) recognition, significant limitations with the initial dataset were encountered, sourced from MNIST. While MNIST has been instrumental for benchmarking machine learning models, we found that its "too perfect" nature—comprising images that lack the diversity and complexity of real-world scenarios—did not translate well for the intended purposes. Specifically, the dataset presented diversity issues and was too limited in representing the nuanced variations of ASL signs, including differences in hand shapes, sizes, and orientations, as well as the presence of dynamic movements for certain letters. Recognizing these shortcomings, the best idea was to create a proprietary dataset, leveraging OpenCV and MediaPipe for image capture and processing. This approach made it possible to generate a more comprehensive and diverse collection of hand gesture images, encompassing a wider array of real-world conditions. By customizing our dataset, the aim was to enhance the robustness and applicability of our CNN, ensuring it is better equipped to accurately recognize ASL spelling in diverse and practical environments.
300 pictures for each hand (left/right) and for each letter, about 12,000 images total. Each image is 128x128 in size, and black/white. Each letter is contained in a folder, and labeled with the appropriate hand (left or right) and the epoch at which it was taken.
Utilizing the OpenCV library and MediaPipe for hand detection, the pipeline continuously monitors video input from a webcam, identifying hand positions and movements. This pipeline processes each frame to detect hand gestures, and when a new gesture is detected, it captures a grayscale image of the hand. To maintain data relevance and reduce redundancy, it compares consecutive images using histogram comparison for significant differences, discarding those too similar and thus capturing only distinct gestures.

The LeNet Architecture was chosen due to it being a common, simplistic, and one of the first architecture to be used in this space. It was created by Yann LeCun back in 1998 while working at Bell Labs. It has gone through multiple iterations since then. This consists of four main layers which are the Convolution, ReLU, Pooling, and Classification Layer.
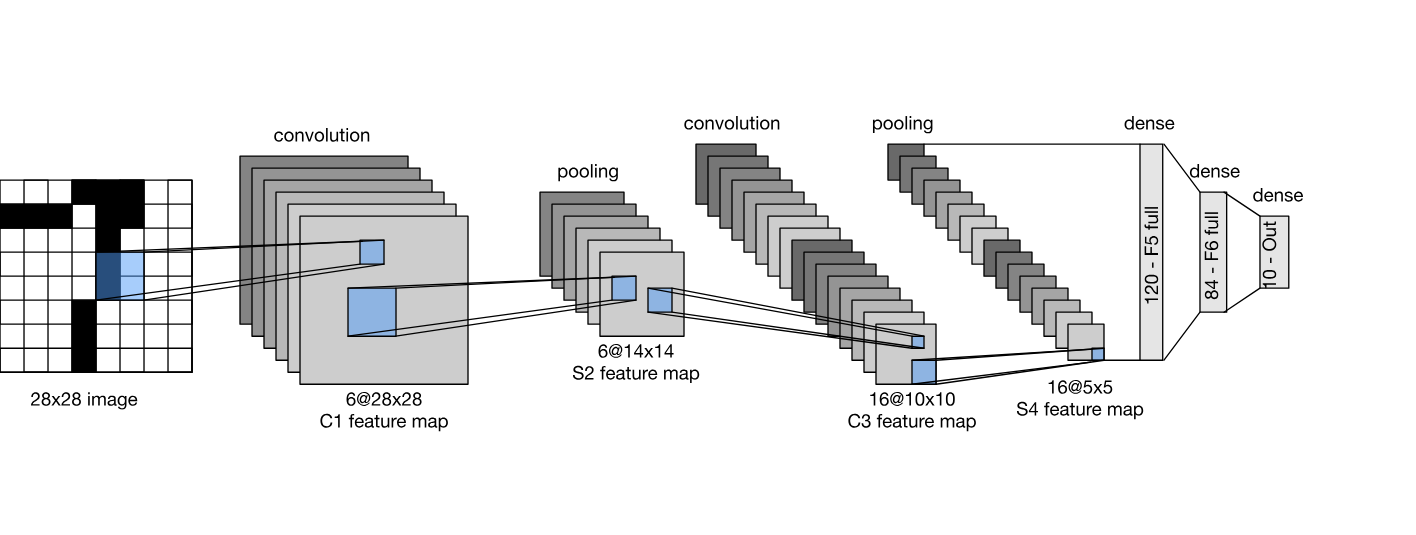
The hyperparameters were initialized as below:
Initialized the kernel as a size of 9 x 9 and a stride of 9 due to the fact this will reduce the sub-image down to a 3 x 3 matrix. The weights were also initialized using Xavier initialization.
Initialize the weights using a Gaussian Distribution due to it being the best fit following a fully connected layer.
Utilized a Learning rate of 0.00001 and stoppage of 10E-7 to keep the model from stopping too soon
Multiple saddle points where observed in the learning of this model and ADAM helped mitigate the model from being stuck
Iterated over each image and performed the sliding DOT product by taking a filter and sliding over portions of the image. This required looping through the Height and Width of the Kernel while being bound by the images Height and Width. This can be a cumbersome due to our O(n) time be reliant on Image Count (IMC), Kernel height (KNH), and Kernel width (KNW) leaving us with a time:
Utilized a Toeplitz matrix which is a matrix where it's diagonals and sub-diagonals are constant. These Toeplitz matrices are then stacked on top of and adjacent to one another based off the the resulting sub-image dimensions. This then allows for a the creation of sequence when flattened out. This will match the orientation of the flattened image mimicking the sliding DOT product, but as a matrix computation instead of a iterative loop in order to generate a flattened Kernel. Our O(n) would be reliant on Image size (IMS), Kernel height (KNH), and Kernel width (KNW) leaving us with a time of
8 times faster!!
| Non optimized | Optimized | ∆ | |
|---|---|---|---|
| 100 epochs | 23 sec | 2 min | 97 sec |
| 10k epochs | 39 min | 5 hrs | 4.3 hrs |
In future developments, the goal is to evolve this system into one capable of real-time hand gesture recognition by integrating the trained CNN directly with the live feed capture process.
This means reversing the current ingestion pipeline's flow: instead of saving composite images for later processing, the script will dynamically create these composites in real-time and immediately feed them into the CNN for gesture classification. As the camera captures video, the script will continuously extract sequences of the frames that exhibit potential hand movements, preprocess these sequences into the standardized composite format, and then input them into the CNN model.
It would also be possible to recognize movement using the three-picture approach we discussed earlier. This would drastically increase the training time, as the inputs would change in size from 128x128 to 384x128. A major challenge with this approach would be the timing of the movement: a slower or faster hand movement would probably change the accuracy of the predicted result.
Currently it's still a challenge to blow up the image leaving the Convoluted layer in order to run our Max Pooling layer. Going forward it's going to be necessary to use Maxing pooling while the images are still flattened. Doing so we would remove an extra flattening layer step from both forward and backwards and tremendously reduce over compute time for the Max Pooling layer.
Training data is shown in blue and validation data is shown in orange.
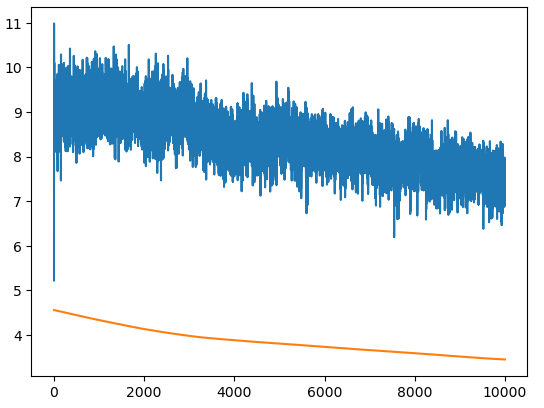
An accuracy of 90% was obtained after 10,000 epochs.
Throughout this project - a perhaps too ambitious journey to implement live hand gesture recognition using CNNs - challenges were faced in achieving real-time hand recognition and comprehensive hand movement recognition, these efforts have not been without significant breakthroughs. The most notable accomplishment of this work has been the substantial improvement in the efficiency of our CNN model, making it 8 times faster than the starting point.